Un mémo sur comment identifier le numéro id des volumes disques d’un serveur et l’appliquer au service de supervision sous Centréon via la commande snmpwalk.
Supervision des volumes disques sous Centréon
Par défaut, sous Centréon il existe différents modèles de services pour superviser des volumes disques :

Chaque modèle de service dépend de la commande de vérification : check_centreon_remote_storage

La commande de vérification check_centreon_remote_storage se présente de la façon suivante :
$USER1$/check_centreon_snmp_remote_storage -H $HOSTADDRESS$ -n -d $ARG1$ -w $ARG2$ -c $ARG3$ -v $_HOSTSNMPVERSION$ -C $_HOSTSNMPCOMMUNITY$
Les valeurs qui identidient le volumes disque sont :
- -n : pour identifier la partition, exemple : /home
- -d : pour identifier le numéro id de la partition correspondant à -n
Cependant, suivant les serveurs, les valeurs -n et -d ne correspondent toujours pas ! Et, dans Centréon on se retrouve avec des erreurs de type : Unknown -d: number expected… try another disk – number
Ma solution consiste à modifier la commande check_centreon_remote_storage pour n’utiliser que l’option -d et lui associer le bon numéro d’id correspondant à la valeur hrStorage de la commande snmpwalk.
Identifier le numéro id des volumes disque d’un serveur avec snmpwalk
A partir du serveur Centréon :
snmpwalk IP hrStorage -v2c -c public | grep STRING
Exemple de sortie :
HOST-RESOURCES-MIB::hrStorageDescr.1 = STRING: Physical memory HOST-RESOURCES-MIB::hrStorageDescr.3 = STRING: Virtual memory HOST-RESOURCES-MIB::hrStorageDescr.6 = STRING: Memory buffers HOST-RESOURCES-MIB::hrStorageDescr.7 = STRING: Cached memory HOST-RESOURCES-MIB::hrStorageDescr.8 = STRING: Shared memory HOST-RESOURCES-MIB::hrStorageDescr.10 = STRING: Swap space HOST-RESOURCES-MIB::hrStorageDescr.31 = STRING: / HOST-RESOURCES-MIB::hrStorageDescr.39 = STRING: /run HOST-RESOURCES-MIB::hrStorageDescr.41 = STRING: /dev/shm HOST-RESOURCES-MIB::hrStorageDescr.42 = STRING: /run/lock HOST-RESOURCES-MIB::hrStorageDescr.43 = STRING: /sys/fs/cgroup HOST-RESOURCES-MIB::hrStorageDescr.61 = STRING: /var/lib/vz HOST-RESOURCES-MIB::hrStorageDescr.63 = STRING: /run/lxcfs/controllers HOST-RESOURCES-MIB::hrStorageDescr.76 = STRING: /run/cgmanager/fs
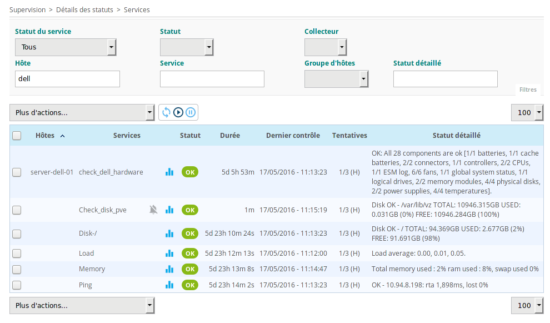
Si je souhaite superviser l’espace disponible de la partition /var/lib/vz, j’indiquerais dans ma commande l’id numéro 61. Exemple en ligne de commande :
cd /usr/lib/nagios/plugins ./check_centreon_snmp_remote_storage -H IP -d 61
Sortie de la commande :
Disk OK - /var/lib/vz TOTAL: 10946.315GB USED: 0.031GB (0%) FREE: 10946.284GB (100%)|size=11753516310528B used=32890880B;10578164679475;11165840495001;0;11753516310528
Mise en place de la solution dans Centréon
Dupliquer la commande de vérification check_centreon_remote_storage avant d’apporter les modifications. Aller dans le Menu Configuration puis Commandes :

Sélectionner la nouvelle commande qui se nomme check_centreon_remote_storage_1 et modifier comme suit :
$USER1$/check_centreon_snmp_remote_storage -H $HOSTADDRESS$ -d $ARG1$ -w $ARG2$ -c $ARG3$ -v $_HOSTSNMPVERSION$ -C $_HOSTSNMPCOMMUNITY$
Pour faire simple, j’ai supprimé l’option -n.
Modifier le service sur l’hôte en changeant le modèle de service par « Generic-service » et ajouter la commande de vérification check_centreon_remote_storage_pve avec ses valeurs associées :

Pour la prise en compte des modifications Par Centréon, ne pas oublier d’appliquer la nouvelle configuration en rechargeant le collecteur :

Après quelques secondes, la partiton /var/lib/vz de mon serveur Proxmox est supervisée par Centréon :